JVM 內存結構、垃圾回收機制與參數調優 數據處理與存儲服務的核心支持
在現代企業級應用中,數據處理和存儲服務通常面臨著高并發、大數據量和低延遲的嚴苛要求。Java虛擬機(JVM)作為這些服務的主流運行環境,其內部的內存管理機制、垃圾回收(GC)策略以及參數調優能力,直接決定了服務的性能、穩定性和可擴展性。深入理解JVM的內存結構與GC原理,并進行有效的參數調優,是構建高效、可靠數據處理與存儲支持服務的技術基石。
一、JVM內存結構:數據處理的運行時舞臺
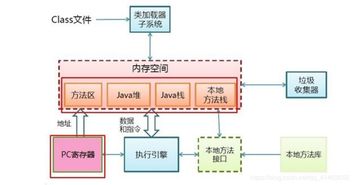
JVM內存區域主要劃分為線程共享區和線程私有區,共同構成了應用程序數據處理的運行時舞臺。
- 線程共享區(所有線程共享)
- 堆(Heap):這是JVM管理的最大一塊內存區域,也是垃圾回收器工作的主要場所。幾乎所有的對象實例和數組都在這里分配內存。堆是數據處理服務的核心區域,存放著業務數據對象、緩存對象等。為了優化GC性能,堆內部分為新生代(Young Generation)和老年代(Old Generation)。新生代又細分為Eden區和兩個Survivor區(S0, S1)。
- 方法區(Method Area):用于存儲已被虛擬機加載的類信息、常量、靜態變量、即時編譯器編譯后的代碼等數據。在JDK 8及之后,永久代(PermGen)被元空間(Metaspace)取代,元空間使用本地內存,減少了OutOfMemoryError的風險。
- 線程私有區(每個線程獨有)
- 程序計數器(Program Counter Register):指向當前線程正在執行的字節碼指令地址。
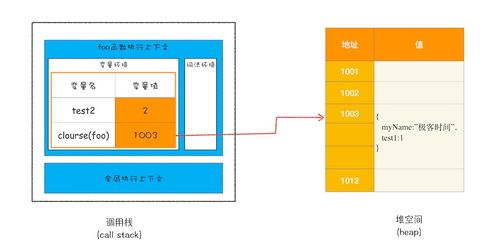
- Java虛擬機棧(Java Virtual Machine Stacks):每個方法執行時會創建一個棧幀,用于存儲局部變量表、操作數棧、動態鏈接、方法出口等信息。局部變量表存放了基本數據類型和對象引用。
- 本地方法棧(Native Method Stack):為JVM使用到的本地(Native)方法服務。
對于數據處理服務,堆內存的規模和結構是性能的關鍵。過小的堆容易引發頻繁的GC甚至內存溢出;過大的堆則可能導致單次GC停頓時間過長。合理劃分新生代與老年代的比例,能有效管理不同生命周期對象,提升GC效率。
二、垃圾回收(GC)機制:自動內存管理引擎
GC負責自動回收堆中不再使用的對象,釋放內存。其核心是“分代收集”理論,針對不同區域采用不同的算法。
- 新生代GC(Minor GC):對象優先在Eden區分配。當Eden區滿時,觸發Minor GC。存活的對象會被移動到其中一個Survivor區,年齡加1。隨后Eden區和正在使用的Survivor區被清空。對象在Survivor區之間來回拷貝,直到年齡達到閾值(默認15),則晉升到老年代。新生代GC通常使用復制算法,速度快,但會浪費一部分內存(Survivor區)。
- 老年代GC(Major GC / Full GC):當老年代空間不足、方法區空間不足或調用
System.gc()時,可能觸發Full GC,這會同時清理新生代、老年代和方法區。Full GC速度慢,停頓時間長,對服務影響巨大,應盡量避免。老年代GC通常使用標記-清除或標記-整理算法。
- 主流垃圾收集器:
- Serial / Serial Old:單線程收集器,簡單高效,適用于客戶端或小內存應用。
- Parallel Scavenge / Parallel Old:JDK 8默認組合,多線程并行收集,追求高吞吐量。適合后臺計算、批處理任務。
- CMS(Concurrent Mark Sweep):以獲取最短回收停頓時間為目標,大部分工作可與用戶線程并發執行。適合對延遲敏感的服務,但會產生內存碎片。
- G1(Garbage-First):JDK 9及之后的默認收集器。它將堆劃分為多個大小相等的獨立區域(Region),能預測停頓時間,并優先回收垃圾最多的區域。兼顧吞吐量和低延遲,是大內存、多核處理器的首選,非常適合大規模數據處理服務。
- ZGC / Shenandoah:新一代超低延遲收集器,停頓時間可控制在10毫秒以內,適用于對延遲有極端要求的場景。
三、JVM參數調優:為數據處理服務定制運行時
調優的目標是在給定的硬件資源下,平衡吞吐量、延遲和內存占用。以下是針對數據處理與存儲服務的關鍵調優思路和參數示例。
- 堆內存設置:這是最基礎的調優。
-Xms和-Xmx:設置堆的初始大小和最大大小。通常將它們設為相同值,以避免堆在運行時動態調整帶來的性能波動。例如:-Xms4g -Xmx4g。大小需根據系統總內存和數據量設定,建議不超過物理內存的50%-70%。
-Xmn:設置新生代大小。增大新生代可以減少對象過早進入老年代,但會減小老年代,可能增加Full GC頻率。通常為整個堆的1/3到1/4。也可用-XX:NewRatio設置新生代與老年代的比例。
- 選擇合適的垃圾收集器:
- 對于高吞吐量的批處理任務:可使用默認的Parallel Scavenge/Old,或顯式指定
-XX:+UseParallelGC。
- 對于在線查詢、實時數據處理等對延遲敏感的服務:強烈推薦使用G1收集器。參數:
-XX:+UseG1GC。可以進一步設置預期最大停頓時間:-XX:MaxGCPauseMillis=200(目標200毫秒)。
- 對于內存非常大(如數百GB)且要求極低延遲的場景:可考慮ZGC (
-XX:+UseZGC) 或 Shenandoah (-XX:+UseShenandoahGC)。
- GC日志與分析:開啟GC日志是調優的第一步。
-XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:/path/to/gc.log
- 使用工具(如GCViewer, GCEasy)分析日志,關注:Full GC頻率、單次GC停頓時間、吞吐量(應用運行時間/總時間)。
- 針對數據處理服務的特殊優化:
- 大對象處理:頻繁創建大對象(如大數組)會直接進入老年代,容易引發Full GC。可考慮調整閾值
-XX:PretenureSizeThreshold,或優化代碼使用對象池。
- 元空間(Metaspace):數據處理框架(如Spark、Flink)和依賴眾多,可能加載大量類。需監控并適當限制元空間:
-XX:MaxMetaspaceSize=256m,防止無限制膨脹。
- 直接內存:NIO、Netty等網絡通信或緩存組件會使用直接內存(堆外內存)。其大小受
-XX:MaxDirectMemorySize限制,不足也會引發Full GC。
- 避免顯式System.gc():可通過
-XX:+DisableExplicitGC禁用,但需確保使用的第三方庫(如NIO)不會因此出現問題。
四、實踐:構建穩定的數據處理支持服務
- 監控先行:在生產環境中部署APM工具(如Prometheus + Grafana, SkyWalking)或JMX,實時監控堆內存使用率、GC頻率與耗時、線程狀態等關鍵指標。
- 壓力測試:在上線前,使用模擬真實數據量和訪問模式的壓力測試,觀察JVM表現,并根據GC日志調整參數。
- 循序漸進:調優是一個迭代過程。每次只調整1-2個參數,觀察效果,再決定下一步。沒有一套放之四海而皆準的參數。
- 結合應用特點:不同的數據處理框架(如Spark內存計算、Elasticsearch索引存儲、Kafka消息隊列)對內存和GC有不同偏好,需參考其官方最佳實踐進行配置。
****:JVM的內存結構為數據處理服務提供了靈活而強大的運行時容器,垃圾回收機制是其高效運轉的自動清潔工。通過深入的原理理解和精細的JVM參數調優,我們可以最大限度地發揮硬件潛力,確保數據處理與存儲支持服務在高負載下依然保持高性能、低延遲和高可靠性,從而為上層業務提供堅實的技術支撐。
如若轉載,請注明出處:http://m.hrwqafk.cn/product/9.html
更新時間:2026-06-18 02:05:02